
核心
逻辑回归的目的和结果是“分类”,其中间过程是”回归“,通过回归模型计算出可能性,再加上阈值,可能性超过阈值是一类,低于阈值为一类
Sigmond函数
Sigmond函数为逻辑回归算法的拟合函数:
$$ f(z) = \frac{1}{1 + e^{-z}} $$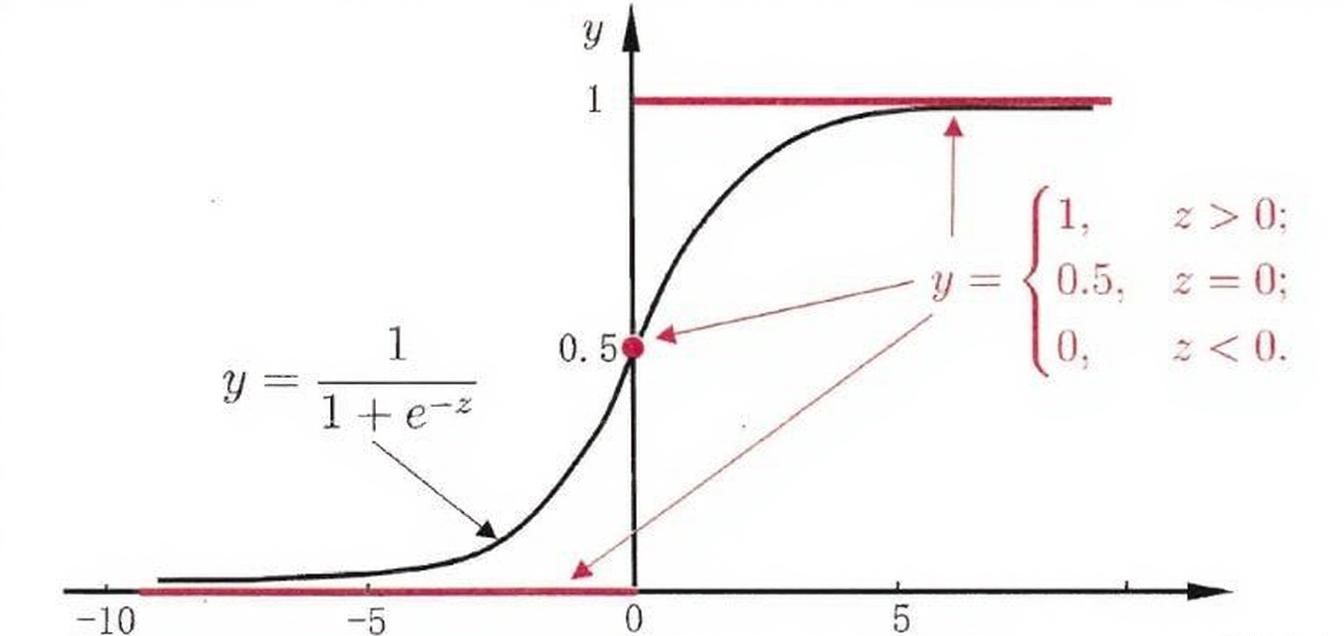
推广至多元
多元线性回归方程的一般形式为:
$$ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p $$矩阵形式为$\boldsymbol{Y}=\boldsymbol{X}\boldsymbol{\beta}$,其中:
$$ \boldsymbol{Y} = \begin{bmatrix} y_{1} \\ y_{2} \\ \vdots \\ y_{n} \end{bmatrix}, \quad \boldsymbol{X} = \begin{bmatrix} 1 & x_{11} & \cdots & x_{1p} \\ 1 & x_{21} & \cdots & x_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_{n1} & \cdots & x_{np} \end{bmatrix}, \quad \boldsymbol{\beta} = \begin{bmatrix} \beta_{0} \\ \beta_{1} \\ \vdots \\ \beta_{p} \end{bmatrix} $$令其为预测为正例的概率P(Y=1),带入Sigmond函数有:
$$ P(Y=1) = \frac{1}{1 + e^{-X\beta}} $$最大似然估计
该方法用于求解方程中的${\beta}$值,该方法的基础为似然函数(理论基础为概率论中的后验概率),即一个事件实际已经发生了,反推在什么参数条件下,这个事件发生的概率最大。
在二分类问题中,$y$ 只取 0 或 1,可以组合起来表示 $y$ 的概率:
$$ P(y) = P(y=1)^{y} P(y=0)^{1-y} $$我们可以把 $y=1$ 代入上式验证下:
- 左边是 $P(y=1)$;
- 右边是 $P(y=1)^{1} P(y=0)^{0}$,也为 $P(y=1)$。
上面的式子,更严谨的写法需要加上特征 $x$ 和参数 $\beta$:
$$ P(y|x, \beta) = P(y=1|x, \beta)^{y}[1 - P(y=1|x, \beta)]^{1-y} $$前面说了,$\frac{1}{1+e^{-x\beta}}$ 表示的就是 $P(y=1)$,代入上式:
$$ P(y|x, \beta) = \left(\frac{1}{1+e^{-x\beta}}\right)^{y}\left(1 - \frac{1}{1+e^{-x\beta}}\right)^{1-y} $$根据最优 $\beta$ 的定义,也就是最大化我们见到的样本数据的概率,即求下式的最大值:
$$ \mathcal{L}(\beta) = \prod_{i=1}^{n} P(y_{i} \mid x_{i}, \beta) = \prod_{i=1}^{n}\left(\frac{1}{1+e^{-x_{i} \beta}}\right)^{y_{i}}\left(1 - \frac{1}{1+e^{-x_{i} \beta}}\right)^{1-y_{i}} $$这个式子来源于$\mathcal{L}(\beta|x) = P(x|\beta)$,即对于某个观测值 $y_i$,似然函数的值 $\mathcal{L}(\beta|y_{i})$,就等于条件概率的值 $P(y_{i}|\beta)$。
另外我们知道,如果事件 A 与事件 B 相互独立,那么两者同时发生的概率为 $P(A)^{*}P(B)$。那么我们观测到的 $y_1, y_2, \ldots, y_n$,他们同时发生的概率就是 $\prod_{i=1}^{n} P(y_{i}|\beta)$。
因为一系列的 $x_i$ 和 $y_i$ 都是我们实际观测到的数据,式子中未知的只有 $\beta$。因此,现在问题就成了求 $\beta$ 在取什么值的时候,$\mathcal{L}(\beta)$ 能达到最大值。
$\mathcal{L}(\beta)$ 是所有观测到的 $y$ 发生概率的乘积,这种情况求最大值比较麻烦,一般我们会先取对数,将乘积转化成加法。
取对数后,转化成下式:
$$ \log\mathcal{L}(\beta) = \sum_{i=1}^{n}\left(\left[y_{i} \cdot \log\left(\frac{1}{1+e^{-x_{i}\beta}}\right)\right] + \left[\left(1-y_{i}\right) \cdot \log\left(1 - \frac{1}{1+e^{-x_{i}\beta}}\right)\right]\right) $$接下来想办法求上式的最大值就可以了,求解前,我们要提一下逻辑回归的损失函数。
损失函数
可以采用残差平方和,带入Sigmond函数有:
$$ Q = \sum_{i=1}^{n} \left( y_i - \frac{1}{1 + e^{-\mathbf{x}_i \boldsymbol{\beta}}} \right)^2 $$因为非凸,容易陷入局部极小,所以对两边取对数,即对数损失函数:
$$ J(\beta) = -\log\mathcal{L}(\beta) = -\sum_{i=1}^{n}\left[y_{i}\log P\left(y_{i}\right)+\left(1-y_{i}\right)\log\left(1-P\left(y_{i}\right)\right)\right] $$对于该问题的求解,可以用梯度下降法